第一章 数据流形和数据拓扑
理解数据的内在价值是数据资产定价的起点。数据的内在价值由其本身的内在结构决定。数据流形和数据拓扑揭示了数据的内在结构和潜在模式:通过分析数据在流形上的分布,我们能够理解数据的局部几何特征和关联性;而通过研究数据的拓扑特征,我们可以把握数据的全局结构和稳定性质。这种多维度的分析对于评估数据的价值至关重要。
数据流形的研究使我们可以量化数据的复杂性、稀缺性和实用性,而数据拓扑分析则帮助我们识别数据的持久特征、结构稳定性和全局模式。这两种方法相辅相成,共同为数据资产的定价提供科学依据:数据流形揭示了数据的几何特征和局部结构,而拓扑分析则捕捉了数据在不同尺度下的本质形态。
只有同时深入了解数据的流形结构和拓扑特征,才能全面准确地评估数据资产的潜在价值,为数据交易和投资决策奠定坚实的基础。数据的几何特征和拓扑性质共同构成了数据价值评估的理论基石,为数据资产的科学定价提供了完整的分析框架。
本章简要的介绍数据流形和数据拓扑的基本概念。
1. 什么是流形(manifold)
在数学中,流形是一个在局部看来像欧氏空间的拓扑空间。简单地说,流形就是每个小区域都与欧氏空间同胚的空间对象,但当这些小区域组合在一起时,整体可能呈现出更复杂的结构。这种局部-整体的关系使得流形成为描述复杂数据结构的理想工具。
举个生活中的例子,地球表面就是一个典型的二维流形。虽然地球整体是球形的,但当我们站在地面上观察周围时,局部区域在我们看来是平坦的。这就是为什么我们可以在小范围内使用平面地图进行导航,而在大范围导航时需要考虑地球的曲率。
流形的严格数学定义:
一个拓扑空间 被称为 维流形,如果满足以下条件:
- 是豪斯多夫空间,即对于 中的任意两点,存在不相交的开集将其分开。
- 满足第二可数公理,即 的拓扑基是可数的。
- 对于 中的每个点 ,存在一个开邻域 和一个开集 ,以及一个同胚映射(称为局部坐标图): 使得 是从 到 的同胚,并且 可以看作是点 在 中的局部坐标。
这里的同胚映射 被称为局部坐标图,它为流形上的点提供了局部坐标系统。局部坐标图的意义在于,它将流形上的局部区域映射到欧氏空间,使得我们可以在局部使用欧氏空间的工具(如微积分)来研究流形。
符号表示:
- 对于所有 ,存在开集 和 ,以及同胚映射 。
如下是Klein瓶的示意图。Klein是一个二维流形,示意图显示的是klein浸入在三维空间中的情况。

关于流形的主要数学定律:
- 维数定理: 流形的每一点都有一个确定的维数,称为其维数(dimension)。这个维数是局部性质,并且在流形的每一点都是唯一的。对于 维流形,每个点的邻域都同胚于欧氏空间 。
例子: 圆周 : 一维流形的典型例子是单位圆 。虽然嵌入在二维平面内,但对于圆周上的每个点,其邻域都与实数轴 同胚。这说明了圆周是一个一维流形,每个小区域看起来都是线性的。
- 嵌入定理(惠特尼嵌入定理): 任意光滑的 维流形都可以光滑嵌入到欧氏空间 中。这里的光滑单射嵌入是指一个光滑的映射,它将流形保形地嵌入到高维欧氏空间中,并且映射本身及其逆映射都是光滑的,没有自相交。即存在一个光滑的单射嵌入映射:
例子: 克莱因瓶: 克莱因瓶是一个非定向的二维流形,无法在三维空间中无自交地嵌入。然而,根据惠特尼嵌入定理,它可以嵌入到四维空间 中而不产生自交。这表明了高维空间中流形嵌入的可能性。
- 子流形定理: 流形的子集在满足一定条件下也构成流形,称为子流形(submanifold)。子流形本身也是一个流形。具体来说,如果映射的秩在某点处达到最大值,那么该点就是子流形的一部分。
例子: 球面上的赤道: 三维欧氏空间中的单位球面 是一个二维流形。球面上的赤道是一个一维子流形,相当于一个嵌入在 中的圆周。赤道的每个点都有一个与 同胚的邻域。
- 切空间与切丛: 在流形的每一点,都可以定义一个与之关联的切空间(tangent space),集合所有的切空间构成流形的切丛(tangent bundle)。切空间是流形在某一点的局部线性近似,可以看作是该点处所有切向量构成的向量空间。切空间是流形在某点处的线性近似。
例子: 山峰上的切空间: 想象一座山的山顶,登山者站在顶点。此时,山顶处的切空间是一个与地平面平行的平面,表示登山者在该点沿各个方向移动的可能性。整个山体的切丛则包含了山体每个点的切空间的集合。
- 斯托克斯定理: 将微积分的基本定理推广到流形上,连接了微分形式的外微分与流形的边界积分。对于流形 和定义在其上的 阶微分形式 ,有:
例子: 电磁学中的麦克斯韦方程组: 斯托克斯定理在电磁学中应用广泛。例如,安培环路定律描述了磁场沿闭合曲线的环量与通过该曲线的电流之间的关系: 这实际上是斯托克斯定理的直接应用,将曲线上的积分转换为曲面上的积分。
- 高斯-博内定理: 将流形的几何性质与拓扑性质联系起来。高斯-博内定理将流形的几何性质(曲率)与拓扑性质(欧拉示性数)联系起来,为我们理解流形的内在结构提供了桥梁。对于紧致、二维的黎曼流形 ,其总曲率与欧拉示性数满足: 其中, 是高斯曲率, 是欧拉示性数。
例子: 多面体的总曲率: 对于一个凸多面体,如正四面体,其总高斯曲率可通过各顶点的角缺损计算,并满足高斯-博内定理。总曲率与该多面体的欧拉示性数之间存在固定关系。
- 帕拉塔-斯迈尔定理: 给出了流形间微分同胚的存在条件,是微分拓扑中的重要结果。帕拉塔-斯迈尔定理是研究流形分类的有力工具,可以帮助我们理解不同维度球面之间的同胚性。
例子: 高维球面的同胚性: 在高维拓扑学中,该定理帮助我们理解不同维度的球面之间何时存在微分同胚。这对于分类高维流形和理解它们的结构至关重要。
1.1 流形的基本性质
流形具有一些重要的基本性质,这些性质帮助我们理解数据的内在结构:
1. 维数的局部唯一性
流形的每一点都有一个确定的维数。这个维数是通过局部坐标系统来定义的 - 如果一个点的某个邻域可以同胚于 n 维欧氏空间,那么我们说这个点的维数是 n。例如:
- 曲线是一维流形,因为它在每点附近都像一条直线
- 曲面是二维流形,因为它在每点附近都像一个平面
- 我们的三维空间就是一个三维流形
2. 嵌入性质
惠特尼嵌入定理(Whitney Embedding Theorem)告诉我们,任何n维光滑流形都可以被嵌入到足够高维的欧氏空间中。具体来说:
这里 表示嵌入映射,它保持了流形的拓扑和几何性质。这个定理对数据分析特别重要,因为它保证了我们可以在更高维的空间中完整地表示复杂的数据结构。
3. 切空间与局部线性化
在流形上的每一点 p,我们都可以定义一个切空间 。切空间可以看作是流形在该点的最佳线性近似,它包含了所有从该点出发的切向量。形象地说:
- 对于曲线,切空间是一条切线
- 对于曲面,切空间是一个切平面
- 对于n维流形,切空间是一个n维向量空间
1.2 流形与数据分析
流形概念在数据分析中的应用基于一个重要观察:现实世界的数据往往具有内在的低维结构。让我们通过几个具体例子来理解:
1. 图像数据的例子
考虑一张 100×100 像素的灰度图像。虽然从原始数据角度看是10000维向量,但实际图像往往位于一个低维流形上。例如,手写数字图像主要由笔画的粗细、倾斜度等少数几个因素决定。
2. 自然语言处理的例子
词向量虽然可能有几百维,但语义相近的词往往分布在低维流形上。例如,"king"、"queen"、"prince"、"princess"这些词的向量之间存在可以用少数几个维度描述的关系。
1.3 流形学习的基本思想
流形学习试图发现数据的内在低维结构。其核心思想可以概括为:
- 局部性原理: 在足够小的邻域内,流形近似于欧氏空间
- 降维思想: 寻找数据的低维表示,同时保持重要的几何结构
- 连续性假设: 相似的数据点在低维表示中应该保持相近
这可以用数学语言表达为:寻找一个映射 ,使得:
其中 ,且 尽可能保持数据的局部几何结构。这里的"保持几何结构"可以有多种理解:
- 保持距离关系(如Isomap算法)
- 保持局部线性关系(如LLE算法)
- 保持概率分布(如t-SNE算法)
2. 流形假设(Manifold Hypothesis)
2.1 基本概念
流形假设是现代机器学习的核心假设之一,它认为现实世界中的高维数据通常位于(或接近于)一个低维流形。这个假设可以形式化地表述为:
存在一个从低维参数空间到高维观测空间的光滑映射 :
这里:
- 是低维潜在表示(latent representation)
- 是生成映射(generating mapping)
- 是内在维数(intrinsic dimension)
- 是观测维数(ambient dimension)
- 通常有
2.2 为什么流形假设是合理的?
流形假设的合理性来自以下几个方面:
1. 物理约束 现实世界的数据生成过程通常受到物理定律的约束。物理约束限制了数据的自由度,使得数据不会在所有维度上都随机变化,而是集中在低维流形上。例如:
- 人脸图像受到面部肌肉运动的约束
- 语音信号受到声带和声道形状的约束
- 人体姿态受到关节活动范围的约束
2. 连续变化原理 自然界中的变化往往是连续的。自然界中的连续变化使得相邻数据点之间存在关联,这些关联性使得数据倾向于分布在低维流形上。比如:
- 视频中相邻帧的变化是连续的
- 温度、湿度等物理量的变化是连续的
- 人的行走动作是连续的姿态变化
3. 数据冗余性 高维数据中的维度往往不是独立的。高维数据中的维度往往不是完全独立的,而是存在相关性,这些相关性使得数据倾向于分布在低维流形上。例如在图像中:
- 相邻像素之间有强相关性
- RGB通道之间存在关联
- 纹理模式具有重复性
2.3 流形假设的数学表述
让我们用更严格的数学语言来描述流形假设:
定义: 给定数据集 , 流形假设认为存在:
- 一个 维流形 ()
- 一个噪声分布 ,用于描述观测数据的误差,由于噪声的存在,观测数据通常会偏离理想的流形。
- 一个生成过程:
这里:
- 是数据点在流形上的投影
- 是观测噪声
- 数据点 位于流形 的邻域内
2.4 流形假设的实际意义
流形假设对机器学习有深远的影响:
1. 维度灾难的缓解 流形假设认为实际数据集中在低维流形上,因此我们可以通过降维技术来消除冗余维度,从而缓解维度灾难。
- 传统的"维度灾难"基于数据均匀分布在高维空间的假设
- 流形假设表明实际数据集中在低维流形上,大大减轻了维度灾难的影响
2. 深度学习的理论基础 神经网络可以视为在学习流形之间的映射,每一层网络都在学习数据流形的某种表示。
- 神经网络可以视为在学习流形之间的映射
- 每一层网络都在学习数据流形的某种表示
3. 数据分析的指导原则 流形假设指导了许多流形学习算法的设计,这些算法的目标是在降维的同时尽可能保留数据的流形结构。
- 降维应该保持数据的流形结构
- 特征提取应该关注数据的内在维度
- 相似性度量应该基于流形上的距离
这些理论见解直接指导了许多实际应用:
- 图像生成中的潜在空间插值
- 语音合成中的声学参数平滑过渡
- 推荐系统中的用户兴趣建模
流形假设的动机
现实世界中,很多高维数据都是由一些潜在的、低维的生成过程引起的。例如:
- 图像数据:一幅图像可能包含数以万计的像素点(高维数据),但这些像素的取值往往由场景中的物体、光照、视角等少数因素决定。
- 语音信号:语音数据可以看作是高维的时间序列信号,但实际由发声器官的状态(如声带、舌头、嘴唇的位置)等低维因素控制。
- 文本数据:一篇文章可以被表示为高维的词向量,但其主题、情感等少数特征起到了主导作用。
流形假设的意义
- 降维:既然数据主要位于低维流形上,那么通过降维技术,可以有效地表示和处理数据,减少计算复杂度和存储需求。
- 特征提取:流形学习方法旨在发现数据的内在结构,提取有意义的低维特征,增强模型的泛化能力。
- 数据可视化:通过将高维数据映射到二维或三维空间,可以更直观地观察数据的分布和聚类特性。
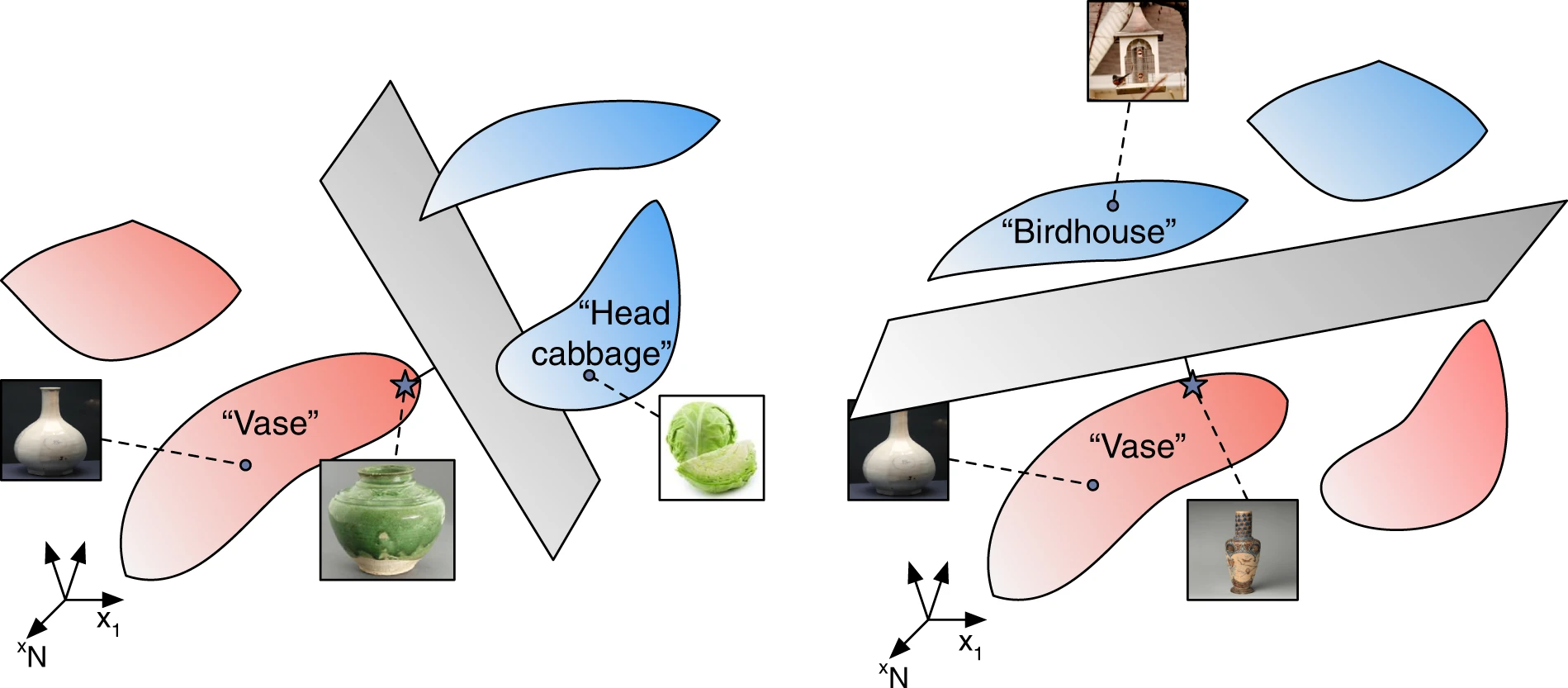
这张图片展示了不同物体在特征空间中的流形结构,以及不同类别在高维空间中如何分布。使用流形假说的概念,这些不同的物体类别(例如"vase"、"head cabbage"、"birdhouse")可以看作高维空间中的流形,它们各自形成了具有特定形状和方向的区域。每个类别的流形代表了该类别物体在视觉特征空间中的连续分布。
图中的平面分隔了这些流形,表示一个决策边界,用于将不同类别区分开。每个类别流形中的点则代表了具体的物体样本。流形的形状反映了类别内特征的变化,例如某一类物体在形状或颜色上的差异。通过流形假说,我们可以解释为这些不同类别在高维空间中有着连续而非离散的特征分布,而分类模型的任务就是找到一个适当的分隔面,以区分这些流形。
支持流形假设的证据
- 实验观察:在很多实际数据集上,降维技术如主成分分析(PCA)能够以少数几个主成分解释大部分数据方差,表明数据确实集中在低维子空间或流形上。
- 成功的应用:流形学习方法(如Isomap、LLE、t-SNE)在图像、语音、文本等领域取得了成功,进一步支持了流形假设的有效性。
流形假设的局限性
- 复杂流形结构:某些数据的流形结构可能非常复杂,存在自相交、边界等问题,增加了学习难度。
- 噪声和测量误差:现实数据往往受到噪声影响,导致数据偏离理想的流形,影响流形学习的效果。
- 维度诅咒:尽管流形维度较低,但在高维空间中,流形仍可能呈现出高复杂度,处理和计算上依然具有挑战性。
流形假设的局限性实例
虽然流形假设在很多情况下是有用的,但是它在处理某些类型的数据时也存在局限性。例如,对于一些高度复杂和无规则性的高维数据,数据点可能并不集中在一个低维的光滑流形上。
实例:高维噪声数据
考虑一个高维空间中的随机噪声数据集。设想我们有一个由独立同分布的随机变量构成的高维数据集,其中每个维度的数据都随机且彼此独立。在这种情况下:
- 数据分布特性:数据点在高维空间中均匀分布,不存在任何内在的低维结构或模式。
- 流形学习的困难:由于数据没有低维流形结构,任何尝试将数据降维到较低维度的流形学习方法都会丢失大量信息,无法捕获数据的本质特征。
- 降维效果不佳:降维后的数据可能无法保留原始数据的统计特性,导致在后续的任务(如分类、聚类)中表现不佳。
这个实例展示了当数据本身不满足流形假设,即数据并非集中在低维流形上时,流形学习方法的局限性。在处理纯随机噪声数据或具有高度复杂性的分布时,流形假设并不适用,依赖于该假设的算法可能无法有效地分析和处理数据。
流形假设并非适用于所有类型的数据。在面对高度非结构化或复杂的数据集时,需要谨慎考虑流形假设的适用性,并选择合适的数据分析和建模方法。
3. 数据流形(Data Manifold)
数据流形的概念是流形假设在数据科学领域的具体应用。数据流形的核心思想是数据分布在低维流形上。数据流形是指数据在高维空间中分布所形成的低维光滑流形结构。虽然数据存在于高维空间,但由于数据内部的关联性和约束,实际有效的自由度可能远小于表观维度。这意味着数据点实际上被限制在高维空间中的一个低维流形上。
举例来说,人脸图像识别是数据流形理论在实际应用中的典型例子。尽管每幅人脸图像在数字化后会形成一个高维空间中的点(例如,一个 像素的灰度图像可以表示为10,000维的向量),但人脸的变化实际上由有限的因素控制,这是因为人脸图像的变化是由面部肌肉运动、头部姿态、光照条件等因素决定的,这些因素是相对独立的,并且可以被视为低维参数空间的坐标:
- 表情变化(Expression):微笑、哭泣、惊讶等不同的面部表情导致的肌肉形变。
- 头部姿态(Pose):头部的转动、倾斜和俯仰等不同角度。
- 光照条件(Illumination):光源方向、强度和数量的变化导致的明暗差异。
- 年龄变化(Age):随着年龄增长带来的面部特征变化。
- 遮挡(Occlusion):如眼镜、帽子、头发等对面部的部分遮挡。
这些因素可以视为控制人脸图像变化的参数,其组合形成了一个低维的参数空间。在高维的像素空间中,人脸图像的数据点被限制在由这些参数空间映射得到的低维流形上。
利用数据流形的概念,可以采用各种流形学习方法来处理和分析人脸图像数据。例如:
- 局部线性嵌入(Locally Linear Embedding, LLE):通过保持数据局部邻域的线性关系,将高维人脸数据降至低维空间,揭示其内在的流形结构。
- 等距映射(Isomap):基于保持数据点之间的测地距离,实现高维到低维的降维过程,保留数据的全局几何特征。
- 拉普拉斯特征映射(Laplacian Eigenmaps):利用拉普拉斯矩阵的谱分解,捕获数据流形的局部和全局结构信息。
这些方法的应用可以带来多种益处:
- 提高识别准确率:在低维流形空间中,人脸数据的类别区分更加明显,有助于提升人脸识别算法的性能。
- 降噪与特征提取:通过流形学习,可以有效地去除高维数据中的噪声,提取对识别任务最有用的特征。
- 数据可视化:将高维人脸数据映射到二维或三维空间,便于直观地观察和分析数据的分布和聚类情况。
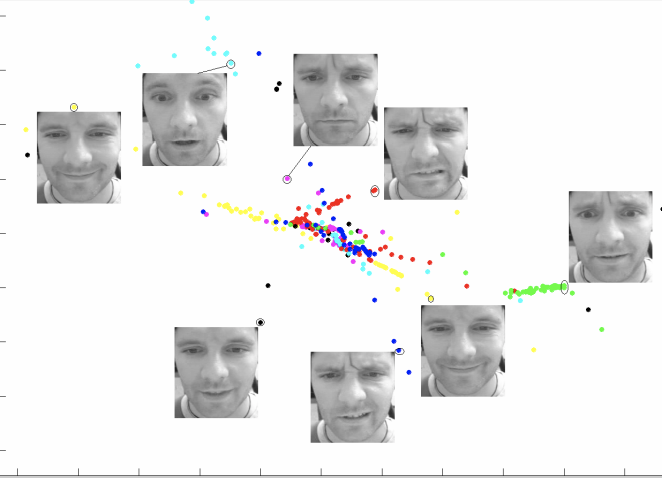
这张图片展示了人脸图像在高维特征空间中的流形结构。图中的每个散点代表一张人脸图片,通过降维技术(如 t-SNE 或 PCA)将其嵌入到二维平面上。相似的表情(如微笑、皱眉)聚集在一起,形成局部连续的流形结构,表明这些表情在高维空间中是相邻的。不同表情之间的距离则表明它们在特征空间中的差异性。因此,这张图显示了表情特征如何在高维空间中"流动",形成一个自然的、连续的分布,从而揭示了人脸数据的内在几何结构。
3.1 深度学习
深度学学习是一种基于人工神经网络的机器学习方法,深度学习是一种表示学习方法,它通过多层神经网络来学习数据的分层表示。特别是使用多层神经元网络结构来学习数据的表征和特征。它模拟人脑的神经元连接方式,通过层层抽象,从原始数据中自动提取高级特征,从而实现对复杂数据的分析和处理。
近年来,深度学习在多个领域取得了显著的成就:
-
计算机视觉:在图像分类、目标检测、图像分割、人脸识别等任务中,深度学习模型如卷积神经网络(CNN)已经超越了传统方法的性能。例如,ResNet、DenseNet等模型在ImageNet等大型数据集上取得了接近人类水平的识别准确率。
-
自然语言处理:在机器翻译、文本生成、情感分析等任务中,循环神经网络(RNN)、长短期记忆网络(LSTM)、Transformer等模型推动了技术进步。特别是BERT、GPT系列模型的出现,使得机器生成的文本更加流畅和符合语义。
-
语音识别与合成:深度学习技术使得语音识别的准确率大幅提升,并实现了高质量的语音合成,应用于智能助手、语音输入等领域。
-
游戏AI与强化学习:通过深度强化学习,AlphaGo、AlphaZero等模型在围棋、国际象棋中击败了顶尖的人类选手,展示了人工智能在复杂决策中的潜力。
深度学习之所以能够取得如此成功,关键原因在于:
-
丰富的数据内在规律:实际世界的数据往往蕴含着复杂且有价值的模式和结构,例如图像中的边缘、纹理,语言中的语法、语义。这些内在规律为模型的学习提供了基础。
-
强大的特征学习能力:深度学习模型具有自动提取特征的能力,不再依赖人工设计特征。多层网络结构能够从低级特征(如像素、单词)逐步抽象出高级特征(如物体、句子意义),有效捕获数据的内在规律。
-
大量的数据和计算资源:大规模的数据集和高性能计算资源(如GPU、TPU)的可用性,使得训练深层神经网络成为可能,模型能够在海量数据中学习到更精细的模式。
-
先进的算法与结构:如卷积神经网络、循环神经网络、注意力机制等模型结构的提出,极大地增强了模型对特定类型数据的处理能力。此外,优化算法的改进(如Adam优化器)、正则化方法(如Dropout)等也提升了模型的性能。
深度学习取得如此重大成功的关键一点是数据本身蕴含的丰富内在规律,深度学习能够学习数据的内在规律,而不是依赖人工设计的特征。
3.2 数据流形的数学描述
在深度学习中,流形假设起着至关重要的作用。深度神经网络通过多层非线性变换,试图捕获数据的内在结构,将高维数据映射到低维流形表示。每一层网络都在提取数据的特征,将数据逐步投影到更能体现其本质的表示空间中。
基于流形假设,数据科学中的两个基本假设可以被总结出来:
-
流形分布定律:同一类别的高维数据往往集中在某个低维流形附近。这意味着,在数据空间中,同类数据不是随机分布的,而是聚集在具有相似特征的区域内。深度学习模型通过学习这些区域,可以有效地对数据进行分类和预测。
-
聚类分布定律:不同类别的数据对应于流形上的不同区域,这些区域之间的距离足够大,使得不同类别的数据可以被清晰地区分开来。这表明,数据在流形上的分布呈现出天然的聚类结构。深度学习通过识别和利用这些聚类结构,增强了模型的判别能力。
流形假设提供了理解高维数据结构的视角,深度学习模型则通过复杂的网络结构和学习算法,将这一假设转化为实际的数据处理能力。凭借对流形分布和聚类分布的充分利用,深度学习在图像识别、语音处理、自然语言处理等领域取得了卓越的成果。
给定数据集 , 数据流形可以用以下数学工具描述:
1. 局部结构 在点 的邻域内,数据流形可以用切空间近似:
这里 是局部主方向,可以通过局部PCA估计。
2. 测地距离 两点间的实际距离应该沿着流形测量:
其中 是连接 和 的流形上的路径。
3. 概率分布 数据在流形上的分布可以用条件概率描述:
3.3 深度学习中的数据流形
深度学习与数据流形有着密切的关系:
1. 表示学习视角
- 每一层网络将输入数据映射到新的特征空间
- 理想情况下,这个映射会逐渐"展平"数据流形,深度学习模型的目标是通过逐层变换,将复杂的数据流形逐渐‘展平’,使其在特征空间中更容易被分类或分析。
3.3 深度学习的几何解释
深度学习中的流形映射与微分几何解释
在深度学习模型中,神经网络被视为一系列非线性映射的组合,将输入数据从一个高维空间转换到另一个空间。这些映射可以用微分几何中的流形理论来解释,从而更深入地理解深度学习的工作原理。
神经网络层作为流形之间的映射
设输入数据分布在一个高维流形 上,神经网络的每一层都可以被视为一个从流形到流形的可微映射,神经网络的每一层都构成一个可微映射,从而保证了数据流形在不同层之间平滑的变换。:
其中,, 是第 层的输出流形。通过复合映射,神经网络实现了从输入流形到输出流形的转换:
流形上的函数与特征提取
在微分几何中,流形上的函数可以描述局部和全局的几何特性。神经网络的激活函数和权重矩阵可以被视为定义在流形上的光滑函数,并且在训练过程中不断地调整,以逼近数据流形的几何结构。
-
激活函数:引入非线性,使得模型能够逼近任意复杂的函数,提供了流形之间非线性的可微映射。
-
权重矩阵:决定了映射的方向和尺度,对应于流形上的切向量场。
通过调整权重和偏置,神经网络在训练过程中学习到数据流形的几何结构,实现对数据特征的提取和表示。
优化过程中的几何视角
深度学习的训练过程是一个优化问题,目标是在参数空间中找到使损失函数最小化的参数组合,深度学习的优化目标是在参数流形上找到损失函数的最小值。这个过程可以用黎曼几何中的概念来描述:
-
参数空间:所有可能的网络参数组合构成的空间,可以视为一个高维流形。
-
损失函数曲面:在参数空间上定义的标量场,每个点的值表示在该参数下模型的损失。
-
梯度下降法:在参数流形上沿着损失函数的最速下降方向移动,相当于在黎曼流形上寻找最短路径(测地线),以快速逼近损失函数的局部最小值。这里所使用的梯度是黎曼梯度,它是损失函数在参数流形上的最速下降方向,可以通过将欧式梯度投影到参数流形的切空间上得到。
深度学习中的曲率与泛化能力
微分几何中的曲率概念可以帮助理解深度学习模型的泛化能力:
-
平坦的最小值区域:在参数空间中,如果损失函数的最小值区域曲率较小(即更平坦),模型对参数扰动的不敏感性更高,泛化能力更强。平坦的最小值区域意味着模型对于参数的微小扰动不敏感,因此模型具有更好的鲁棒性和泛化能力。
-
尖锐的最小值区域:曲率较大的区域,对参数变化非常敏感,可能导致过拟合,泛化能力较差。尖锐的最小值区域意味着模型对参数非常敏感,容易陷入局部最小值,并且容易过拟合训练数据,泛化能力较差。
通过将深度学习中的神经网络架构、训练过程和优化方法与微分几何中的流形、映射、曲率和测地线等概念对应起来,我们可以从几何的角度更深入地理解深度学习模型的内部机制。这种视角有助于揭示模型的本质特性,为改进深度学习算法提供新的思路。
3.4 深度学习与流形学习
3.4.1 流形学习
流形学习(Manifold Learning) 是一种非线性降维方法,旨在从高维数据中揭示低维的内在流形结构。流形学习假设高维数据实际上分布在一个低维的非线性流形 上,目标是找到一个映射函数 ,其中 ,使得高维数据在低维空间中得到有效表示,同时保持原始数据的几何或拓扑特性。
常见的流形学习方法包括:
- 等距特征映射(Isomap):基于测地距离的保持,通过最短路径计算近似测地距离。
- 局部线性嵌入(LLE):保持数据局部邻域的线性重构关系。
- 拉普拉斯特征映射(Laplacian Eigenmaps):利用图拉普拉斯算子捕捉数据的局部结构。
3.4.2 深度学习
深度学习(Deep Learning) 是一类基于多层神经网络的机器学习方法,通过组合多层非线性变换来学习数据的多级表示。深度学习模型试图逼近复杂的非线性函数,以从高维数据中抽取有用的特征,实现从输入到输出的映射。
数学上,深度神经网络的输出可以表示为嵌套的非线性函数:
其中, 是输入数据, 是输出, 表示第 层的非线性映射, 是模型的参数集合。
3.4.3 流形学习与深度学习的关系
流形假设(Manifold Hypothesis) 是两者的共同基础,认为高维数据实际上集中在一个低维的流形结构上。深度学习和流形学习都试图捕捉这种低维结构,以实现数据的有效表示和处理。
- 特征表示:深度学习的隐藏层可以被视为将数据从原始空间映射到新的特征空间,逐层逼近数据的流形结构。
- 非线性映射:两者都利用非线性函数实现从高维空间到低维空间的映射。
3.4.4 流形学习与深度学习的区别
-
模型结构和训练方式
- 流形学习:通常是无参数或非参数模型,主要采用无监督学习方式,通过优化某种代价函数直接寻找低维嵌入。例如,LLE 通过最小化重构误差,找到保持局部结构的低维表示。
- 深度学习:基于参数化的深层网络结构,包含大量的可训练参数,通过反向传播算法在监督或半监督的情况下进行训练,最小化任务相关的损失函数。
-
泛化能力和可扩展性
- 流形学习:由于方法的非参数性和计算复杂度限制,对新样本的映射和大规模数据处理存在困难。
- 深度学习:具有良好的泛化能力,能够高效处理大规模数据,并对新样本进行快速预测。
-
目标函数和优化
- 流形学习:目标函数通常与数据的几何性质相关,如保持邻域关系或测地距离,优化过程涉及特征分解或凸优化。
- 深度学习:目标函数与特定任务相关,如分类误差或重建误差,优化过程采用梯度下降等一阶方法,可能受到非凸性影响。
-
理论基础
- 流形学习:基于流形理论和非线性动力系统,强调数据的几何和拓扑结构。
- 深度学习:涉及函数逼近理论、信息论和统计学习理论,关注模型的表达能力和泛化性能。
3.4.5 数学定理与理论差异
-
流形学习中的定理
- Nash 嵌入定理:任何黎曼流形都可以等距地嵌入到欧氏空间中,保证了流形在高维空间中的表示。
- 拉普拉斯-Beltrami 算子性质:用于捕捉流形的内在几何结构,常用于构建流形学习的目标函数。
-
深度学习中的定理
- 通用逼近定理:单隐藏层神经网络在给定足够的神经元时,可以逼近任何连续函数。
- 深度网络的表达能力定理:深度网络能够以指数级更少的参数表示某些函数,较浅层网络更具优势。
3.4.6 实际应用中的区别
- 流形学习:多用于数据可视化、降维和探索性数据分析,帮助理解数据的内在结构。
- 深度学习:广泛应用于图像识别、自然语言处理、语音识别等领域,解决实际的预测和分类问题。
深度学习和流形学习在目标上都有揭示高维数据的低维结构,但方法和应用领域有所不同。流形学习侧重于利用数据的几何性质进行降维,强调保持流形的结构,而深度学习通过训练深层网络从数据中学习特征表示,注重模型的预测性能。两者在理论基础和实际应用上都有所区别,但在理解和处理高维数据方面具有互补的作用。
3.5 数据的内蕴结构
根据流形假设,数据具有以下内蕴结构:
- 低维度性:数据的有效维度远小于观测空间的维度。有效维度是指能够解释数据变化的最少维度数。
- 局部线性性:在流形的小邻域内,数据呈现线性特性。
- 全局非线性性:整体上,数据分布体现出复杂的非线性结构,需要非线性方法来建模。
深度学习通过多层非线性变换,逐步提取数据的高级特征,能够有效捕捉数据的内在结构。其中,**自动编码器(Autoencoder)**利用编码器将数据映射到低维潜在空间,再通过解码器重建原始数据,学习到的数据表示即为内在结构。其模型表示为:
**卷积神经网络(CNN)则在图像等数据中,通过局部感受和权值共享,提取空间局部特征,捕捉数据的内在结构。而生成对抗网络(GAN)**通过生成器和判别器的博弈,学习数据的分布,生成与真实数据相似的样本,进一步捕获数据的内在结构。
相对于深度学习,流形学习专注于揭示数据的低维流形结构,常用的方法有:等距映射(Isomap),利用测地距离替代欧氏距离,保持数据的全局几何结构;局部线性嵌入(LLE),保持数据的局部邻域几何结构,假设数据在局部邻域内可以用线性方式重构;以及拉普拉斯特征映射(LE),利用拉普拉斯矩阵,保持数据的局部邻域关系。
在应用与实践中,首先是降维与可视化,即将高维数据映射到低维空间,便于数据分析和可视化展示。其次是特征提取,获取数据的低维表示,提升机器学习模型的性能。最后是数据生成与复现,通过学习数据的内在结构,生成新的数据样本,用于数据增强等。
实例分析中,在人脸识别领域,人脸图像高维且受光照、表情等影响,但其变化受少数因素控制。使用深度学习模型(如深度卷积神经网络)提取的人脸特征,可以有效表示其内在结构,提高识别准确率。在自然语言处理方面,词嵌入模型(如 Word2Vec)将高维稀疏的词语表示为低维稠密向量,捕捉词语之间的语义关系,体现了数据的内在结构。
在方法的运用上,模型选择需要根据数据特性和任务需求,选择合适的深度学习或流形学习模型。参数调节则涉及调整模型的超参数(如学习率、网络层数)以更好地捕获数据结构。最后,模型融合通过结合深度学习和流形学习的方法,提升模型的表达能力和泛化性能。
通过深度学习和流形学习的方法,可以洞察数据的一些内在结构和特征,但不是全部。单纯依靠几何和统计的方法不足以全面捕捉数据的复杂性。为了更深入地理解数据的整体形态和潜在模式,需要引入拓扑学的视角。拓扑数据分析(Topological Data Analysis,TDA)作为一种新兴的方法,是从全局的角度揭示数据的形状特征,帮助发现传统方法难以识别的数据深层次结构。
4. 拓扑数据分析(TDA)
拓扑数据分析(Topological Data Analysis, TDA)是一种结合拓扑学和数据科学的现代分析方法,它通过研究数据的形状和结构特征来获取洞察。TDA的核心思想是数据具有"形状",这种形状包含了重要的信息,可以通过持续同调(Persistent Homology)等工具来捕获。
TDA的主要技术包括:将点云数据转化为简单复形(Simplicial Complex)序列,计算持续图(Persistence Diagram)和条形码(Barcode)来表示拓扑特征的"寿命",以及使用Mapper算法构建数据的拓扑骨架。这种方法特别适合分析高维、非线性和噪声数据,因为它对数据变形具有鲁棒性,能够捕获数据的本质拓扑特征。在实践中,TDA已被成功应用于基因组学、材料科学、金融市场分析等领域,帮助发现传统方法难以识别的数据模式和结构。TDA不仅提供了一种新的数据分析视角,也为数据价值评估提供了基于拓扑特征的量化指标。
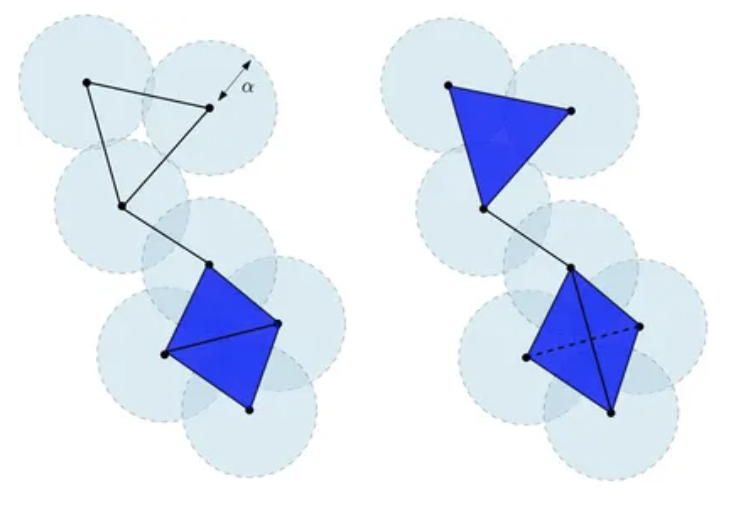
图例中所示平面 中有限点云的切赫复形 (左)和维托里斯-里普斯复形 (右)。 的底部是两个相邻三角形的并集,而 的底部是由四个顶点及其所有面构成的四面体。切赫复形的维数是2。维托里斯-里普斯复形的维数是3。
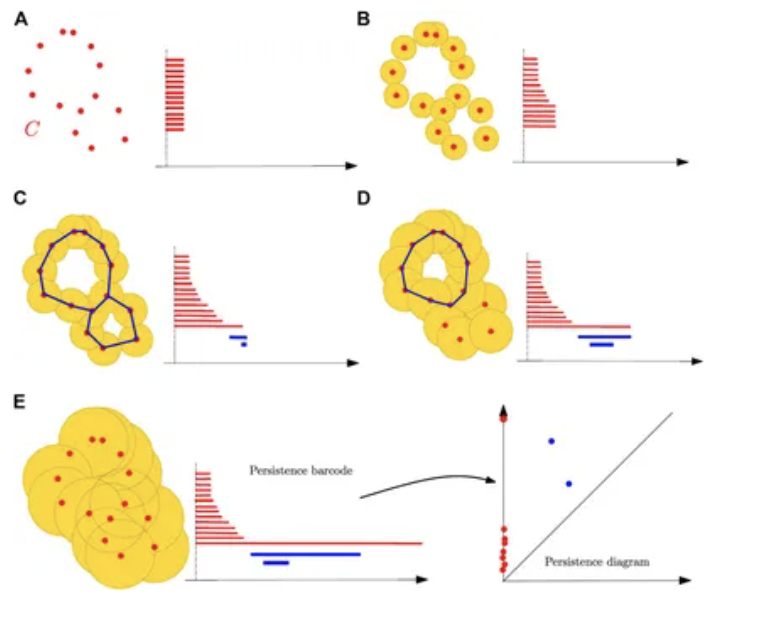
点云距离函数的子水平集过滤以及随着球体半径增加构造其持续条形码的过程。球体并集中的蓝色曲线表示与条形码中蓝色条相关的一维循环。持续图最终由持续条形码定义。
(A) 当半径 r = 0 时,球体的并集简化为初始有限点集,每个点对应一个零维特征,即连通分量;在 r = 0 时为每个特征的诞生创建一个区间。
(B) 一些球体开始重叠,导致一些连通分量合并而消失;持续图通过在相应区间消失时添加终点来记录这些死亡。
(C) 新的分量已合并,形成单个连通分量,因此除了剩余分量对应的区间外,所有与零维特征相关的区间都已结束;出现了两个新的一维特征,在其诞生尺度上产生两个新的区间(蓝色)。
(D) 两个一维循环中的一个已被填充,导致其在过滤中消失以及相应蓝色区间的结束。
(E) 所有一维特征都已消失;只剩下长的(且永不消失的)红色区间。与前面的例子一样,最终的条形码也可以等价地表示为持续图,其中每个区间(a,b)由 中坐标为(a,b)的点表示。直观地说,条形码中的区间越长,或等价地,图中相应点离对角线越远,相应的同调特征在过滤中就越持久,因此越重要。还要注意,对于给定半径 r,相应球体并集的第 k 个贝蒂数等于包含 r 的 k 维同调特征对应的持续区间数。因此,持续图可以被视为一个多尺度拓扑特征,它编码了球体并集在所有半径下的同调以及其随 r 值变化的演化。
4.1 TDA的主要数学定理
-
持续同调基本定理:
- 任何持续模都可以被唯一分解为区间模的直和
- 持续图完全表征了持续同调群的代数结构
- 形式化表示:
-
稳定性定理:
- 对于两个紧致度量空间的持续图,其瓶颈距离有上界
- 保证了TDA方法对噪声的鲁棒性
-
Nerve定理:
- 将覆盖的神经复形与原空间的同伦等价性联系起来
- 对于一个好的覆盖,其神经复形与原空间同伦等价
-
Mapper算法收敛定理:
- 在合适条件下,Mapper输出会收敛到原始空间的Reeb图
- 为Mapper算法提供了理论保证
4.2 TDA的实际应用案例
-
生物医学领域:
- 乳腺癌亚型识别:通过分析基因表达数据的拓扑特征
- 蛋白质构象分析:研究蛋白质折叠过程中的构象变化
- 示例:使用持续同调分析基因表达数据
-
材料科学:
- 材料微观结构分析:研究材料的孔隙分布和连通性
- 相变过程研究:捕捉材料在相变过程中的结构变化
- 应用:分析多孔材料的结构特征
-
金融市场分析:
- 市场结构研究:分析金融资产之间的关联性
- 风险评估:识别市场的系统性风险模式
- 实例:股票市场网络分析
-
图像处理与计算机视觉:
- 形状识别:基于拓扑特征的物体识别
- 图像分割:利用持续同调进行图像分割
- 应用:目标检测中的形状描述
-
社交网络分析:
- 社区结构识别:发现网络中的社区和层次结构
- 信息传播模式:分析信息在网络中的扩散特征
- 示例:社区检测
TDA不仅提供了一种新的数据分析视角,还为数据资产定价提供了创新路径:通过识别数据集中持久的拓扑特征(如反映不同市场状态下数据分布模式的零维、或一维拓扑特征的寿命长短),我们可以量化数据在多样市场条件下的稳定性与关联结构的持久性。这些拓扑不变量可以与金融资产定价理论中的风险溢价结构相类比,从而为数据类资产的定价模型提供有效的定性与定量输入。
5. 数据流形与数据拓扑的异同
数据流形与数据拓扑是数据分析领域中刻画高维数据结构的重要概念。二者都涉及对数据的内在几何和拓扑结构的理解,但在理论基础和应用上存在一定的区别。
5.1 数据流形
数据流形理论假设高维数据实际上位于比原始空间低维的嵌入式流形上。即给定的高维数据集 ,假定存在一个 维流形 (其中 ),使得数据点集中在 上或其附近。数据流形理论的主要目标是通过降维或嵌入技术,如 Isomap、LLE、t-SNE 等,将高维数据映射到低维空间,同时保留数据的几何结构。
5.2 数据拓扑
数据拓扑,特别是基于拓扑数据分析(TDA)的方法,更关注数据的全局拓扑特征,如连通性、孔洞和空腔等。通过构建如持续同调、持续条形码等工具,TDA 能够在不同尺度下捕捉数据的拓扑特征,从而揭示数据的形状和结构,而不局限于特定的维度或几何形状。
5.3 二者的相同点
-
关注数据的内在结构:数据流形和数据拓扑都试图理解数据的内在结构,超越单纯的坐标表示,挖掘数据点之间的本质关联。
-
抗噪性和鲁棒性:二者都具备一定的抗噪性,能够在一定程度上忽略数据中的噪声和异常值,专注于数据的核心结构。
-
高维数据分析:两种方法都适用于高维数据的分析,帮助研究者克服维度灾难的问题。
5.4 二者的不同点
-
理论基础不同:数据流形基于流形理论和微分几何,侧重于局部几何结构的保留;而数据拓扑基于代数拓扑和同调理论,关注全局拓扑性质。
-
关注尺度不同:数据流形方法通常专注于数据的局部结构,保持近邻关系;而数据拓扑方法则在不同尺度下分析数据,捕捉全局拓扑特征。
-
应用目标不同:数据流形主要用于降维、可视化和特征提取,强调数据的嵌入表示;数据拓扑则用于形状分析、模式识别和结构发现,强调数据的拓扑不变量。
-
算法工具不同:数据流形采用如 PCA、MDS、LLE、Isomap 等降维算法;数据拓扑采用持续同调、Čech 复形、Rips 复形等拓扑计算工具。
在数据资产定价的背景下,数据流形分析侧重于发现可为定价模型所用的低维特征表示,帮助降低模型复杂度与提高估值的精确度;拓扑分析则从全局结构出发,识别数据在不同市场条件下长期存在的结构特征,为定价模型提供一种稳定性和鲁棒性评价的度量。二者相辅相成,为后续的数据资产定价框架构建起从局部几何特征到全局拓扑特征的多层次分析基础。
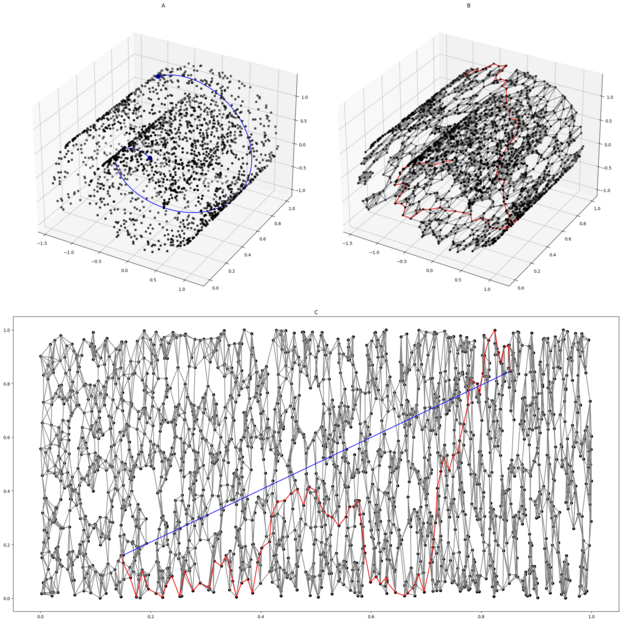
实验
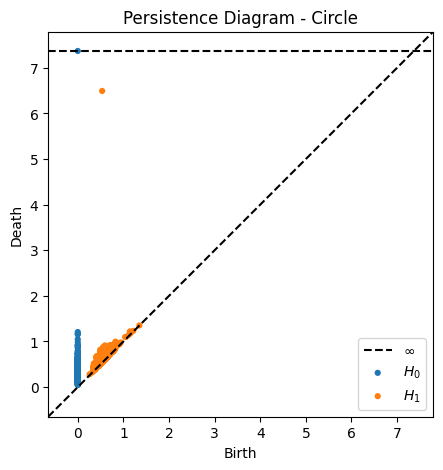
![]()
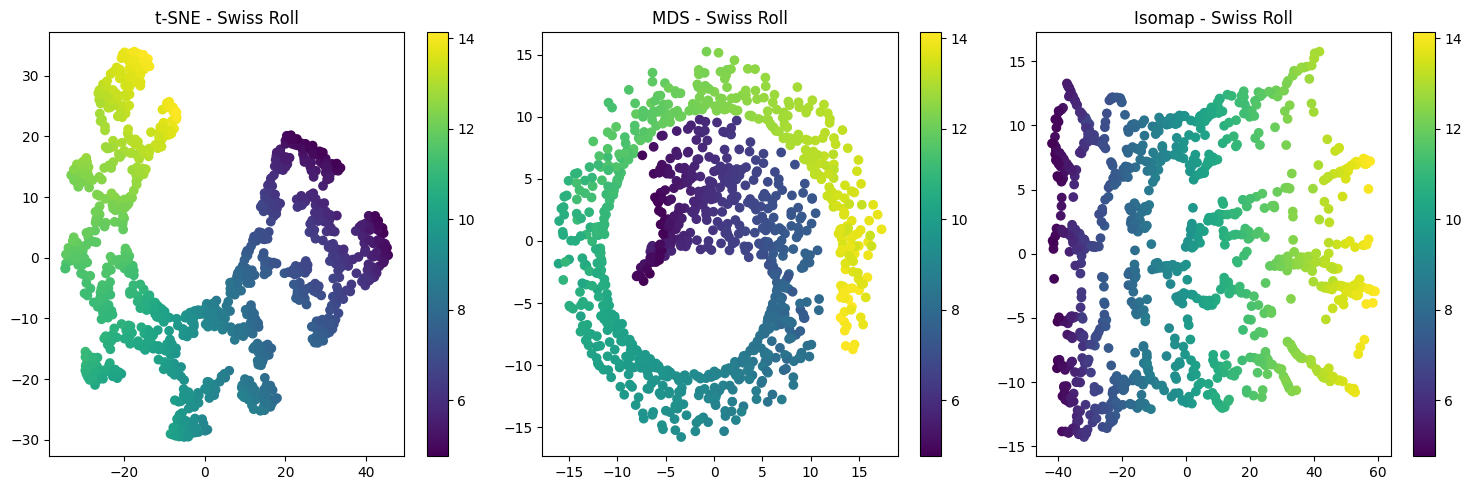
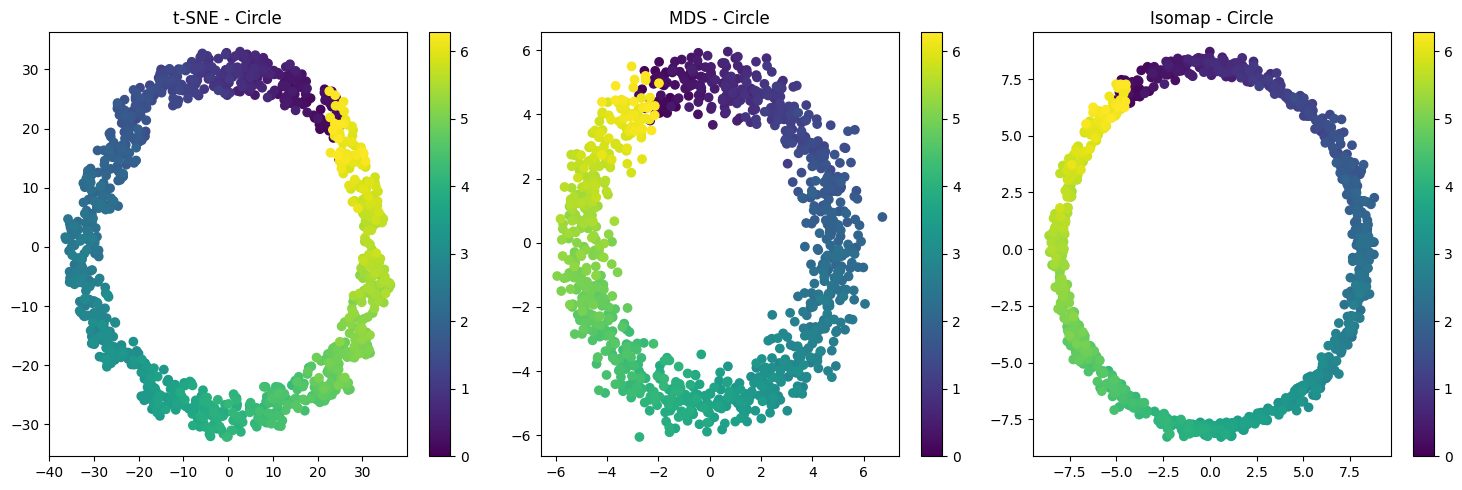
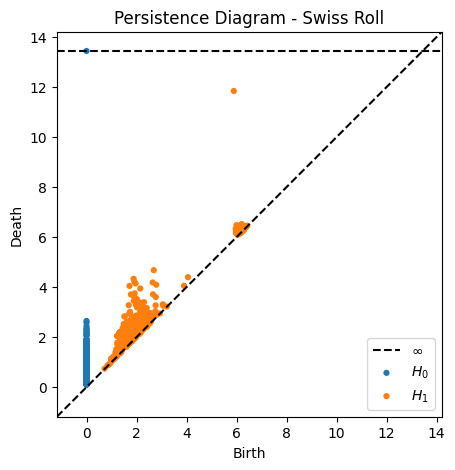
数据流形与数据拓扑为我们理解数据的本质结构和稳定性特征提供了理论基础。在数据资产定价中,数据的价值很大程度上取决于其结构稳定性、稀缺性和对决策的增益能力。通过流形和拓扑分析,我们能够在高维数据中捕捉潜在的低维结构、辨识持久性的特征模式,并发现数据在不同市场条件下的稳健性与稳定形态。这些信息为后续构建基于数据特质的定价模型提供了坚实依据。下一章中,我们将基于这些几何与拓扑分析的成果,进一步探讨数据价值的起源及其度量方法。