第二章 数据价值的起源
数据的价值源于其所包含的信息。数据本身只是一些符号和数字的集合,但通过分析和处理这些数据,我们可以从中提取出有用的信息。这些信息可以帮助我们理解复杂的现象、做出明智的决策、预测未来的趋势以及发现新的知识和洞见。
信息的获取过程通常涉及对数据的收集、清洗、分析和解释。高质量的数据能够提供准确、及时和相关的信息,从而在决策过程中发挥重要作用。例如,在商业领域,企业可以通过分析销售数据来了解市场需求,优化库存管理,制定营销策略,从而提高盈利能力。在科学研究中,数据分析可以揭示自然现象的规律,推动技术创新和科学进步。
然而,数据的价值不仅取决于其自身,还取决于我们对其进行处理和分析的能力。先进的数据分析技术和工具,如机器学习、人工智能和大数据分析,能够从海量数据中挖掘出有价值的信息,提升数据的利用价值。因此,数据的价值不仅在于其所包含的信息量,还在于我们能够从中提取和利用这些信息的能力。
2.1 从瞎子摸象到冷冻电镜技术
瞎子摸象的两种场景
场景一:瞎子之间各自不交换信息
在这个场景中,几个瞎子被带到一头大象面前,他们被要求描述大象的样子。由于他们无法看到,只能通过触摸来感知大象的形状。每个瞎子触摸大象的不同部位,例如象鼻、象腿、象耳等。由于他们没有交换信息,每个人只能根据自己触摸到的部分来描述大象。
- 一个触摸到象鼻的瞎子可能会说:“大象像一条粗大的蛇。”
- 另一个触摸到象腿的瞎子可能会说:“不对,大象像一根粗壮的柱子。”
- 触摸到象耳的瞎子则会说:“你们都错了,大象像一把大扇子。”
由于每个瞎子只触摸到大象的一部分,他们的描述各不相同,甚至相互矛盾。最终,他们无法达成一致的结论,每个人都坚持自己的观点。这种情况下,信息的孤立和缺乏交流导致了对整体的误解。
场景二:瞎子之间充分交换信息
在这个场景中,几个瞎子同样被带到一头大象面前,他们被要求描述大象的样子。但这次,他们在触摸大象的不同部位后,开始相互交流和分享各自的感受和发现。
- 触摸到象鼻的瞎子说:“我感觉大象的鼻子像一条粗大的蛇。”
- 触摸到象腿的瞎子回应:“我触摸到的象腿像一根粗壮的柱子。”
- 触摸到象耳的瞎子补充道:“而我触摸到的象耳像一把大扇子。” ...
通过充分的交流和信息共享,他们逐渐意识到每个人触摸到的只是大象的一部分。通过整合各自的信息,他们可以拼凑出大象的整体形象。数学上可以证明,通过足够的信息交换和整合,瞎子们可以联合起来识别出大象的全貌。
冷冻电镜技术:瞎子摸象的实现
冷冻电镜技术本质上就是瞎子摸象的第二种场景的实现。通过对样本的不同部分进行成像,并将这些信息整合起来,科学家们能够重建出样本的三维结构,从而获得对其整体形态的准确理解。
冷冻电镜技术的原理
冷冻电镜(Cryo-Electron Microscopy, Cryo-EM)是一种用于观察生物大分子和细胞结构的高分辨率成像技术。其基本原理包括以下几个步骤:
-
样本制备:
- 样本被快速冷冻到液氮温度(约-196°C),以保持其天然状态并防止辐射损伤。快速冷冻的过程可以形成无定形冰,而不是晶体冰,从而避免了冰晶对样本结构的破坏。这个过程类似于瞎子摸象场景中,确保大象保持静止状态供瞎子触摸。
-
数据采集:
- 冷冻样本被放置在透射电子显微镜(TEM)中进行成像。TEM的工作原理是通过加速电子束穿过样本,利用电磁透镜系统控制电子束的路径。穿过样本的电子与样本相互作用,形成二维投影图像。这相当于瞎子摸象场景中的每个瞎子从不同角度触摸大象。
-
图像处理:
- 采集到的二维图像经过对齐、分类和平均处理,以提高信噪比和分辨率。通过对大量图像进行统计分析,可以消除噪声和变形,提取出样本的真实结构信息。
-
三维重建:
- 利用计算机算法将处理后的二维图像进行三维重建。常用的方法包括单颗粒重构(Single Particle Reconstruction)和电子断层扫描(Electron Tomography)。单颗粒重构适用于对称性较高的样本,而电子断层扫描则适用于复杂的细胞和组织样本。
-
结构解析:
- 重建出的三维结构可以用于进一步的结构解析和功能研究。科学家们可以通过分析三维结构,了解生物大分子的构象变化、相互作用和功能机制。
冷冻电镜技术的优势在于其能够在接近生理条件下观察生物样本,避免了传统方法中样本制备过程对结构的破坏。此外,冷冻电镜技术不需要晶体化样本,适用于研究难以结晶的生物大分子,如膜蛋白和大分子复合物。
近年来,随着冷冻电镜技术的发展和电子显微镜分辨率的提高,科学家们已经能够解析出原子级分辨率的生物大分子结构。这为生命科学研究提供了强有力的工具,推动了结构生物学、药物设计和分子生物学等领域的进步。
数学证明:从二维投影重构三维结构
冷冻电镜技术能够通过大量的二维投影图像重构出样本的三维结构,这一过程可以通过数学上的逆投影原理(Inverse Projection Principle)来解释。以下是这一原理的简要证明:
-
投影定理:
-
在傅里叶变换的框架下,投影定理(Projection-Slice Theorem)指出,一个三维物体的二维投影的傅里叶变换等于该物体的三维傅里叶变换在相应平面上的切片。具体来说,设 是三维物体的密度函数,其在平面 上的投影为:
则 的傅里叶变换 等于 的傅里叶变换 在 平面上的切片:
-
-
逆投影原理:
- 根据投影定理,我们可以通过采集不同角度的二维投影图像,获得三维物体在不同平面上的傅里叶切片。设 是物体在角度 下的投影,其傅里叶变换为 。通过对所有角度的投影进行傅里叶变换,我们可以得到三维傅里叶空间中的一系列切片。
-
重建三维结构:
- 通过将这些切片组合起来,我们可以重建出三维物体的傅里叶变换 。然后,通过对 进行逆傅里叶变换,我们可以得到原始的三维密度函数 :
- 其中, 表示逆傅里叶变换。
-
实际应用:
- 在冷冻电镜技术中,样本的二维投影图像是从不同角度采集的。通过对这些图像进行傅里叶变换,并利用逆投影原理,我们可以重建出样本的三维结构。这一过程通常需要大量的计算和图像处理技术,以确保重建结果的准确性和分辨率。
数学证明:冷冻电镜技术与瞎子模型的本质相同
在冷冻电镜技术中,我们通过从不同角度采集样本的二维投影图像,利用数学上的逆投影原理重构出样本的三维结构。这一过程可以通过数学的群论来解释。
-
群的定义:
- 在数学中,群(Group)是一个由元素组成的集合,并且在集合上定义了一种二元运算,使得该集合在此运算下满足封闭性、结合性、单位元存在性和逆元存在性。设 是一个群, 是单位元,,则有:
- 封闭性:对于任意 ,有 。
- 结合性:对于任意 ,有 。
- 单位元存在性:存在单位元 ,使得对于任意 ,有 。
- 逆元存在性:对于任意 ,存在逆元 ,使得 。
- 在数学中,群(Group)是一个由元素组成的集合,并且在集合上定义了一种二元运算,使得该集合在此运算下满足封闭性、结合性、单位元存在性和逆元存在性。设 是一个群, 是单位元,,则有:
-
冷冻电镜技术中的群作用:
- 在冷冻电镜技术中,我们可以将样本的不同角度的二维投影图像视为群 的元素。设 是三维物体的密度函数,其在不同角度 下的投影为 。这些投影图像可以通过群作用 进行变换,表示为 ,其中 是一个旋转操作。
-
瞎子摸象的群作用:
- 在瞎子摸象的第二个场景中,每个盲人通过触摸大象的不同部位来描述大象的形状。我们可以将每个盲人的触摸视为群 的元素。设 是大象的整体形状,其在不同盲人触摸下的局部信息为 。这些局部信息可以通过群作用 进行变换,表示为 ,其中 是一个局部触摸操作。
-
群作用的等价性:
- 在冷冻电镜技术和瞎子摸象的场景中,群作用的本质是一样的。通过不同角度的投影图像或局部触摸信息,我们可以获得样本或大象的局部信息。利用群作用的封闭性和结合性,我们可以将这些局部信息整合起来,重构出样本的三维结构或大象的整体形状。
-
重建过程的数学证明:
- 设 是一个群, 是三维物体的密度函数,其在不同角度 下的投影为 。通过群作用 ,我们可以获得一系列投影图像 。利用逆投影原理,我们可以将这些投影图像的傅里叶变换 组合起来,重建出三维物体的傅里叶变换 ,进而通过逆傅里叶变换得到原始的三维密度函数 。
2.2 信息的数学表达
冷冻电镜技术通过从不同角度采集大量的二维投影图像,利用数学上的逆投影原理重构出样本的三维结构。这一过程类似于将瞎子摸象的各个局部信息整合起来,形成对大象的完整认知。
在大数据分析中,我们面临着比冷冻电镜技术更高维度的数据。尽管数据维度增加,但背后的数学原理依然适用。从数据流形和数据拓扑的视角来看,冷冻电镜技术与大数据分析存在深刻的数学联系。
从流形的角度,冷冻电镜技术本质上是在重建样本所在的三维流形结构。每张二维投影图像可以视为这个三维流形在特定方向上的切片。类似地,高维数据分析中,数据点分布在某个低维流形上,我们通过不同维度的观测获得这个流形的局部切片。设高维数据集 位于流形 上,每个观测视角 对应一个局部坐标图 ,其中 是流形上的开集。这些局部坐标图的拼接重建了整个流形结构。
从拓扑的角度,冷冻电镜技术通过分析不同投影角度下的持续同调特征来重建样本的拓扑结构。每个投影角度捕捉了样本在该方向上的拓扑特征,如连通分支、空洞等。在高维数据分析中,我们同样可以研究数据在不同尺度和视角下的拓扑特征。设 是数据在视角 下的过滤函数,通过计算持续同调群:
其中 是过滤参数, 表示 维同调群。这些持续同调特征的综合反映了数据的全局拓扑结构。
数据是信息在局部空间的投影
从流形的角度,冷冻电镜技术本质上是在重建样本所在的三维流形结构。每张二维投影图像可以视为这个三维流形在特定方向上的切片。类似地,高维数据分析中,数据点分布在某个低维流形上,我们通过不同维度的观测获得这个流形的局部切片。设高维数据集 位于流形 上,每个观测视角 对应一个局部坐标图 ,其中 是流形上的开集。这些局部坐标图的拼接重建了整个流形结构。
从拓扑的角度,冷冻电镜技术通过分析不同投影角度下的持续同调特征来重建样本的拓扑结构。每个投影角度捕捉了样本在该方向上的拓扑特征,如连通分支、空洞等。在高维数据分析中,我们同样可以研究数据在不同尺度和视角下的拓扑特征。设 是数据在视角 下的过滤函数,通过计算持续同调群:
其中 是过滤参数, 表示 维同调群。这些持续同调特征的综合反映了数据的全局拓扑结构。
综上所述,数据是信息在某个局部空间的投影。无论是瞎子摸象、冷冻电镜技术,还是大数据分析,都是通过对数据的整合和分析,来重建全局信息的过程。理解这一点,对于我们全面、准确地分析和利用数据具有重要意义。
信息熵
信息熵(Entropy)是信息论中的一个核心概念,由克劳德·香农(Claude Shannon)在其1948年的论文《通信的数学理论》中提出。信息熵用于度量信息的不确定性或随机性。具体来说,信息熵衡量的是在一个随机变量的所有可能取值中,平均每个取值所包含的信息量。
设有一个离散随机变量 ,其可能取值为 ,对应的概率分布为 ,其中 。信息熵 定义为:
在上述公式中, 通常取以2为底,这样信息熵的单位是比特(bit)。如果取自然对数,则单位是纳特(nat)。
信息熵的值越大,表示随机变量的不确定性越高,包含的信息量也越大。反之,信息熵的值越小,表示随机变量的不确定性越低,包含的信息量也越小。
香农定理
香农定理(Shannon's Theorem),也称为香农信息论的基本定理,主要包括两个部分:香农第一定理(无噪信道编码定理)和香农第二定理(有噪信道编码定理)。
-
香农第一定理(无噪信道编码定理):
香农第一定理指出,对于一个无噪信道,存在一种编码方法,使得信息可以以接近信道容量的速率进行无误传输。信道容量 是信道能够无误传输信息的最大速率,定义为:
其中, 是输入 和输出 之间的互信息, 是输入的概率分布。
-
香农第二定理(有噪信道编码定理):
香农第二定理指出,对于一个有噪信道,如果信息传输速率低于信道容量 ,则存在一种编码方法,使得误码率可以任意小。反之,如果信息传输速率超过信道容量,则无论采用何种编码方法,误码率都无法避免。
费舍尔信息
费舍尔信息(Fisher Information)是统计学中的一个重要概念,用于度量参数估计中的信息量。它由统计学家罗纳德·费舍尔(Ronald Fisher)提出,主要用于评估估计量的精确度。费舍尔信息在参数估计、实验设计和机器学习等领域具有广泛应用。
设有一个参数为 的概率密度函数 ,其中 是观测数据。费舍尔信息 定义为对数似然函数的二阶导数的期望值,即:
其中, 表示期望值, 是对数似然函数。
费舍尔信息的值越大,表示参数估计的精确度越高。费舍尔信息矩阵是费舍尔信息的多维推广,用于多参数估计问题。
克拉美-罗下界
克拉美-罗下界(Cramér-Rao Lower Bound, CRLB)是统计学中的一个重要定理,用于给出参数估计的方差的下界。它表明,对于任意无偏估计量,其方差不能小于费舍尔信息的倒数。具体来说,设 是参数 的无偏估计量,则有:
其中, 表示估计量 的方差, 是费舍尔信息。
克拉美-罗下界为评估估计量的性能提供了一个理论基准,任何无偏估计量的方差都不能低于这个下界。
互信息
互信息(Mutual Information)是信息论中的一个重要概念,用于度量两个随机变量之间的相互依赖性。互信息反映了一个随机变量包含的关于另一个随机变量的信息量。设有两个随机变量 和 ,其联合概率分布为 ,边缘概率分布分别为 和 。互信息 定义为:
互信息的值越大,表示两个随机变量之间的依赖性越强。互信息在特征选择、聚类分析和图像处理等领域具有广泛应用。
卡尔曼滤波
卡尔曼滤波(Kalman Filtering)是一种递归算法,用于估计动态系统的状态。它由鲁道夫·卡尔曼(Rudolf Kalman)提出,广泛应用于信号处理、控制系统和导航等领域。卡尔曼滤波通过结合系统的先验信息和观测数据,递归地更新状态估计。
卡尔曼滤波的基本步骤包括预测和更新两个阶段:
- 预测阶段:根据系统的状态转移模型,预测下一个时刻的状态和协方差矩阵。
- 更新阶段:根据观测数据,更新状态估计和协方差矩阵。
卡尔曼滤波的数学表达如下:
预测阶段:
更新阶段:
其中, 是预测状态, 是预测协方差矩阵, 是卡尔曼增益矩阵, 是观测数据, 是观测矩阵, 是过程噪声协方差矩阵, 是观测噪声协方差矩阵。
信息几何
信息几何(Information Geometry)是研究概率分布空间几何结构的数学理论。它结合了微分几何和信息论的概念,用于分析统计模型和机器学习算法的性质。信息几何的核心思想是将概率分布视为流形,并在其上定义几何结构,如度量、连接和曲率。
-
概率分布流形:
- 概率分布流形是由一组概率分布组成的流形。设 是一个概率分布族,每个分布 由参数 确定,其中 是一个 维向量。概率分布流形 可以表示为 ,其中 是参数空间。
-
Fisher 信息度量:
- Fisher 信息度量是定义在概率分布流形上的度量张量。对于参数 ,Fisher 信息度量 定义为: 其中, 表示期望值, 和 是参数的索引。Fisher 信息度量度量了参数空间中微小变化对概率分布的影响。
-
Kullback-Leibler 散度:
- Kullback-Leibler (KL) 散度是度量两个概率分布之间差异的非对称度量。对于两个概率分布 和 ,KL 散度定义为: 在信息几何中,KL 散度可以用来定义概率分布流形上的距离。
主要定理
-
Cramér-Rao 不等式:
- Cramér-Rao 不等式是统计估计理论中的一个重要结果。它给出了无偏估计量方差的下界。设 是参数 的无偏估计量, 是 Fisher 信息矩阵,则有: 其中, 表示估计量 的方差。Cramér-Rao 不等式表明,任何无偏估计量的方差都不能低于这个下界。
-
Jeffreys Prior:
- Jeffreys Prior 是一种无信息先验分布,用于贝叶斯统计中。它基于 Fisher 信息度量定义,表示为: 其中, 是 Fisher 信息矩阵的行列式。Jeffreys Prior 在参数空间中是平移不变的,适用于没有先验信息的情况。
-
Pythagorean 定理:
- 在信息几何中,Pythagorean 定理描述了概率分布流形上的正交投影性质。设 是概率分布流形上的一个点, 是流形外的一个点, 是 在流形上的正交投影点,则有: 该定理表明,KL 散度在正交投影过程中满足类似于欧几里得空间中的勾股定理。
信息几何为理解和分析复杂统计模型提供了强大的工具。通过将概率分布视为几何对象,我们可以更直观地研究其性质和关系,从而在机器学习和统计推断中获得更深刻的洞见。
2.3 数据价值与信息价值
数据价值与信息价值之间存在几个主要特点,这些特点在信息的数学表达中得到了体现:
-
非线性:
- 数据与信息之间的关系通常是非线性的。简单的数据变换可能会导致信息的显著变化,反之亦然。例如,非线性变换(如对数变换、指数变换)在数据处理中常用于揭示隐藏的模式和关系。信息几何中的Fisher信息度量和KL散度等工具可以帮助我们理解这种非线性关系。
-
非完备:
- 数据通常是不完备的,可能存在缺失值、噪声和不确定性。这种非完备性会影响信息的提取和利用。信息几何中的Cramér-Rao不等式提供了无偏估计量方差的下界,表明在不完备数据下,估计的精度受到限制。非完备数据需要通过数据清洗、插值和建模等方法进行处理,以提高信息的质量。
-
不可逆:
- 数据到信息的转换过程通常是不可逆的。一旦信息从数据中提取出来,原始数据可能无法完全恢复。例如,数据压缩和降维技术在保留主要信息的同时丢失了一些细节。信息几何中的Pythagorean定理描述了KL散度在正交投影过程中的性质,表明信息的丢失是不可避免的。
-
信息的多尺度性:
- 信息可以在不同的尺度上进行分析和提取。数据的多尺度特性使得我们可以从宏观和微观两个层面理解信息。例如,拓扑数据分析(TDA)通过在不同尺度下捕捉数据的拓扑特征,揭示数据的全局结构和局部模式。多尺度分析有助于全面理解数据的内在结构和信息价值。
-
信息的上下文依赖性:
- 信息的价值往往依赖于其上下文和应用场景。同样的数据在不同的背景下可能具有不同的意义和价值。例如,在商业领域,销售数据可以用于市场分析和需求预测;在医疗领域,患者数据可以用于疾病诊断和治疗方案制定。信息几何提供了分析不同上下文中信息变化的工具,帮助我们理解信息的上下文依赖性。
-
信息的动态性:
- 信息是动态变化的,随着时间和环境的变化而变化。数据的时序特性和动态变化需要通过时间序列分析和动态建模来捕捉。例如,卡尔曼滤波器用于动态系统的状态估计,能够在噪声和不确定性下提供实时信息更新。信息几何中的动态度量和连接可以帮助我们理解信息的动态变化。
实验

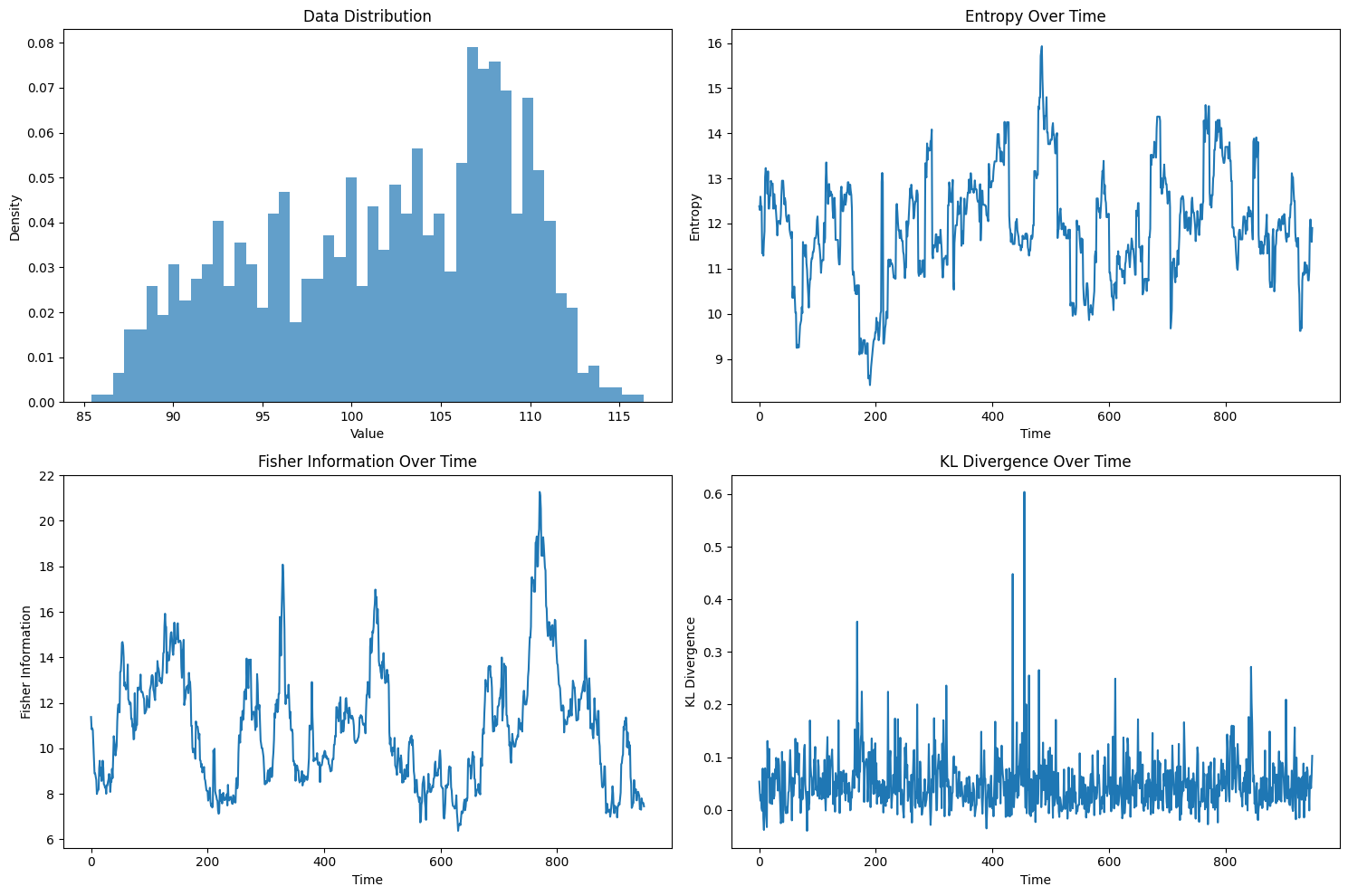
数据价值与信息价值的泛函关系
我们可以通过数学的方法论证数据的价值与信息价值之间的泛函关系。假设数据集为 ,信息为 ,我们可以定义一个泛函 来描述数据到信息的转换过程:
其中, 是一个非线性、非完备、不可逆的映射。为了进一步分析这种关系,我们可以引入一些数学工具和定理。
-
非线性关系: 假设 是一个非线性变换,可以表示为: 其中, 是一个非线性函数。为了揭示这种非线性关系,我们可以使用泰勒展开式对 进行近似: 其中, 是数据的某个参考点, 是 在 处的梯度, 是 在 处的 Hessian 矩阵。
-
非完备性: 数据的不完备性可以通过引入噪声模型来描述。假设数据 包含噪声 ,则有: 其中, 是真实数据, 是噪声。根据 Cramér-Rao 不等式,估计量的方差有下界: 这表明在不完备数据下,信息的提取精度受到限制。
-
不可逆性: 数据到信息的转换过程通常是不可逆的。假设 是一个不可逆映射,则存在信息丢失。根据 Pythagorean 定理,KL 散度在正交投影过程中满足: 这表明信息的丢失是不可避免的。
-
信息的多尺度性: 信息可以在不同的尺度上进行分析。假设 包含多尺度分析,则有: 其中, 表示在第 个尺度上的信息提取。拓扑数据分析(TDA)通过在不同尺度下捕捉数据的拓扑特征,揭示数据的全局结构和局部模式。
-
信息的上下文依赖性: 信息的价值依赖于其上下文。假设 包含上下文依赖性,则有: 其中, 表示上下文信息。信息几何提供了分析不同上下文中信息变化的工具。
-
信息的动态性: 信息是动态变化的。假设 包含动态变化,则有: 其中, 表示时间。卡尔曼滤波器用于动态系统的状态估计,能够在噪声和不确定性下提供实时信息更新。
通过上述分析,我们可以得到数据价值与信息价值之间的泛函关系式: 这个关系式综合了非线性、非完备、不可逆、多尺度、上下文依赖和动态变化等特性,描述了数据到信息的转换过程及其影响因素。
数据价值与信息价值的传导机制
数据价值与信息价值之间的传导机制可以通过对泛函关系式的因变量进行微分分析来定性描述。我们将从非线性、非完备、不可逆、多尺度、上下文依赖和动态变化等特性出发,探讨数据到信息的转换过程及其影响因素。
-
非线性传导机制: 数据到信息的转换过程通常是非线性的。假设 ,其中 是一个非线性函数。通过对 进行微分,我们可以得到信息变化率与数据变化率之间的关系: 其中, 是 的梯度。非线性传导机制表明,数据的微小变化可能导致信息的显著变化,反之亦然。
-
非完备性传导机制: 数据的不完备性会影响信息的提取精度。假设数据 包含噪声 ,则有 。根据 Cramér-Rao 不等式,估计量的方差有下界: 这表明在不完备数据下,信息的提取精度受到限制。非完备性传导机制强调了数据质量对信息价值的影响。
-
不可逆性传导机制: 数据到信息的转换过程通常是不可逆的。假设 是一个不可逆映射,则存在信息丢失。根据 Pythagorean 定理,KL 散度在正交投影过程中满足: 这表明信息的丢失是不可避免的。不可逆性传导机制揭示了在数据处理和转换过程中,信息丢失对信息价值的影响。
-
多尺度传导机制: 信息可以在不同的尺度上进行分析。假设 ,其中 表示在第 个尺度上的信息提取。通过对 进行微分,我们可以得到多尺度信息变化率: 多尺度传导机制表明,不同尺度上的信息提取共同影响信息价值。
-
上下文依赖性传导机制: 信息的价值依赖于其上下文。假设 ,其中 表示上下文信息。通过对 和 进行微分,我们可以得到信息变化率与数据和上下文变化率之间的关系: 上下文依赖性传导机制强调了上下文信息对信息价值的影响。
-
动态性传导机制: 信息是动态变化的。假设 ,其中 表示时间。通过对 进行微分,我们可以得到信息变化率与时间变化率之间的关系: 动态性传导机制表明,数据和信息随时间的变化共同影响信息价值。
范畴论的视角
范畴论(Category Theory)是数学的一个分支,研究数学结构及其之间的关系。范畴论提供了一种统一的语言和框架,用于描述和分析不同数学对象之间的关系。以下是范畴论的一些基本概念:
-
范畴(Category):
- 一个范畴由对象(Objects)和态射(Morphisms)组成。对象可以是任何数学结构,如集合、向量空间等。态射是对象之间的映射,表示对象之间的关系。一个范畴 可以表示为 ,其中 是对象的集合, 是态射的集合。
-
态射(Morphism):
- 态射是对象之间的映射。对于范畴 中的两个对象 和 ,态射 表示从对象 到对象 的映射。态射需要满足结合律和单位元性质。
-
函子(Functor):
- 函子是范畴之间的映射。一个函子 将范畴 中的对象和态射映射到范畴 中的对象和态射。函子需要保持态射的组合和单位元。
-
自然变换(Natural Transformation):
- 自然变换是两个函子之间的变换。设 是两个从范畴 到范畴 的函子,自然变换 是一个将 中的每个对象 映射到 中的态射 的集合,并且对于 中的每个态射 ,有 。
数据价值与信息价值的范畴关系
在范畴论的框架下,我们可以将数据价值和信息价值视为两个范畴,并研究它们之间的关系。
-
数据范畴与信息范畴:
- 设 是数据范畴,其对象是数据集,态射是数据处理过程。设 是信息范畴,其对象是信息集,态射是信息处理过程。
-
数据到信息的函子:
- 我们可以定义一个从数据范畴 到信息范畴 的函子 。这个函子将数据集映射到信息集,并将数据处理过程映射到信息处理过程。具体来说,对于数据范畴中的对象 和态射 ,函子 将其映射为信息范畴中的对象 和态射 。
-
信息价值的自然变换:
- 设 是两个从数据范畴到信息范畴的函子,表示不同的信息提取方法。自然变换 表示在不同信息提取方法之间的转换。对于数据范畴中的每个对象 ,自然变换 表示从信息提取方法 到信息提取方法 的转换过程。
-
范畴关系的意义:
- 通过范畴论的框架,我们可以系统地分析数据价值与信息价值之间的关系。数据到信息的转换过程可以视为范畴之间的函子映射,而不同信息提取方法之间的转换可以视为自然变换。范畴论提供了一种统一的语言,用于描述和分析数据价值与信息价值之间的传导机制。
数据价值与信息价值的对偶性
-
在范畴论中,对偶性(Duality)是一个重要概念。对于每一个范畴 ,我们可以定义一个对偶范畴 ,其对象与 相同,但态射的方向相反。我们可以将数据价值与信息价值视为对偶范畴,表示数据处理与信息提取过程的对偶关系。
-
设 是数据范畴,其对象是数据集,态射是数据处理过程。设 是信息范畴,其对象是信息集,态射是信息处理过程。我们可以定义数据范畴 的对偶范畴 ,其对象与 相同,但态射的方向相反。类似地,我们可以定义信息范畴 的对偶范畴 。
-
对于数据范畴 和信息范畴 ,我们可以定义一个对偶函子 ,将数据范畴的对偶映射到信息范畴的对偶。具体来说,对于数据范畴中的对象 和态射 ,对偶函子 将其映射为信息范畴中的对象 和态射 。
-
设 是两个从数据范畴到信息范畴的函子,表示不同的信息提取方法。我们可以定义对偶自然变换 ,表示在不同信息提取方法之间的对偶转换。对于数据范畴中的每个对象 ,对偶自然变换 表示从信息提取方法 到信息提取方法 的对偶转换过程。
通过对偶范畴和对偶函子的定义,我们可以进一步分析数据价值与信息价值之间的对偶关系。数据处理过程与信息提取过程可以视为对偶范畴之间的映射,而不同信息提取方法之间的对偶转换可以视为对偶自然变换。对偶性提供了一种新的视角,用于理解数据价值与信息价值之间的相互关系。
数据价值起源于信息价值的范畴论解释
在范畴论的框架下,我们可以通过分析数据范畴和信息范畴之间的关系,来解释数据价值起源于信息价值的原因。从范畴论的视角,我们可以将数据和信息视为两个不同的范畴,通过它们之间的函子关系来理解数据价值为什么源于信息价值。
数据范畴与信息范畴
设 为数据范畴,其中对象是数据集,态射是数据处理过程。设 为信息范畴,其中对象是信息集,态射是信息处理过程。数据范畴和信息范畴之间存在一个函子 ,将数据映射到信息。
具体而言,对于数据范畴中的对象 和态射 ,函子 将其映射为信息范畴中的对象 和态射 。这个函子保持了范畴的结构,即:
数据价值的函子表示
数据的价值可以通过其在信息范畴中的像来度量。设 是信息范畴中的价值函数,则数据的价值可以表示为:
这个等式揭示了一个重要事实:数据的价值是通过其携带的信息来体现的。数据本身并不直接产生价值,而是通过转化为信息才获得价值。
自然变换与价值传递
设 是两个不同的信息提取函子,表示不同的数据分析方法。它们之间存在自然变换 ,对于每个数据对象 ,都有一个态射 ,满足自然性条件:
这个自然变换描述了不同信息提取方法之间的价值转换关系。
伴随函子与价值对偶
在某些情况下,存在从信息范畴到数据范畴的函子 ,与 构成伴随对 。这意味着对于任意数据对象 和信息对象 ,存在双射:
这种伴随关系揭示了数据价值和信息价值之间的对偶性。
价值的普遍性
数据到信息的转换过程可以看作是一个普遍构造。对于数据对象 ,其在信息范畴中的像 是最优的信息表示,这种最优性体现在:对于任何其他信息对象 和从 到 的态射 ,存在唯一的态射 使得下图交换:
这个普遍性质说明,数据的价值是通过其最优信息表示来实现的。通过范畴论的视角,我们可以看到,数据价值源于其携带的信息,不同的信息提取方法对应不同的价值实现路径,数据价值和信息价值之间存在对偶关系,数据的最优价值通过其普遍性质来体现。
实际例子:电子商务中的数据价值
为了更好地理解范畴论视角下的数据价值,我们可以结合电子商务中的实际例子来印证前面的几个发现。
数据范畴与信息范畴
在电子商务中,数据范畴 可以表示为用户行为数据集,例如浏览记录、购买记录等。信息范畴 则可以表示为从这些数据中提取出的有用信息,例如用户偏好、购买倾向等。函子 将用户行为数据映射为用户偏好信息。
具体而言,对于数据范畴中的对象 (例如某用户的浏览记录)和态射 (例如从一个用户的浏览记录到另一个用户的浏览记录的映射),函子 将其映射为信息范畴中的对象 (例如用户的购买倾向)和态射 (例如从一个用户的购买倾向到另一个用户的购买倾向的映射)。
数据价值的函子表示
在电子商务中,数据的价值可以通过其在信息范畴中的像来度量。设 是信息范畴中的价值函数,例如用户购买倾向的商业价值,则数据的价值可以表示为:
这个等式揭示了一个重要事实:用户行为数据的价值是通过其转化为用户购买倾向信息来体现的。用户行为数据本身并不直接产生价值,而是通过转化为有用的信息才获得价值。
自然变换与价值传递
在电子商务中,不同的数据分析方法可以看作是不同的信息提取函子。设 是两个不同的信息提取函子,表示不同的数据分析方法,例如基于协同过滤和基于内容推荐的方法。它们之间存在自然变换 ,对于每个数据对象 (例如某用户的浏览记录),都有一个态射 ,满足自然性条件:
这个自然变换描述了不同信息提取方法之间的价值转换关系。例如,基于协同过滤的方法可以通过自然变换转换为基于内容推荐的方法,从而实现不同推荐方法之间的价值传递。
伴随函子与价值对偶
在某些情况下,存在从信息范畴到数据范畴的函子 ,与 构成伴随对 。这意味着对于任意用户行为数据对象 和用户偏好信息对象 ,存在双射:
这种伴随关系揭示了用户行为数据价值和用户偏好信息价值之间的对偶性。例如,通过用户行为数据可以推断出用户的购买倾向,反之,通过用户的购买倾向也可以推断出其行为数据。
价值的普遍性
在电子商务中,用户行为数据到用户偏好信息的转换过程可以看作是一个普遍构造。对于用户行为数据对象 ,其在信息范畴中的像 是最优的信息表示,这种最优性体现在:对于任何其他用户偏好信息对象 和从 到 的态射 ,存在唯一的态射 使得下图交换: